
Hey everybody, today I want to show you how to build an exchange.
Hey everybody, today I want to show you how to build an exchange.
Before we discuss exchanges, let's define what we mean by this term.

So an exchange is a marketplace where people meet to buy and sell securities, derivates and other financial instruments. So far that isn't all that surprising.

Back in the olden days, it was a room of boring people in suits shouting prices at each other and trading pieces of paper. If you don't find that riveting, I don't know what is.

In modern times, an exchange looks more like this. Here, you see the New York Stock Exchange. Big screens showing the latest prices, probably still people shouting at each other. But really, don't be fooled. This is nothing more than a glorified TV studio at this point. The real trading happens somewhere else.

That's here. In a data center. Just computers doing their thing. And that's the reason we are talking about it here today because honestly, I couldn't tell you how it is working on a trading floor.

We now established what an exchange is, and where it is, but we still have to talk about its responsibilities.
One purpose is to keep track of all the buy and sell orders that traders may have for every security traded on the exchange. You wouldn't want your buy order for AAPL to be mixed up, resulting in receiving a MSFT stock at the end of the day.

Another, perhaps even more important, responsibility of an exchange is to match orders in a fair way. This is really why you want to trade at an exchange. Exchanges are regulated environments where they ensure that each order is matched according to a predetermined ruleset.

Now that we've covered what an exchange is and what it does, let's delve into something more intriguing—the heart of the exchange, the engine that drives it forward.
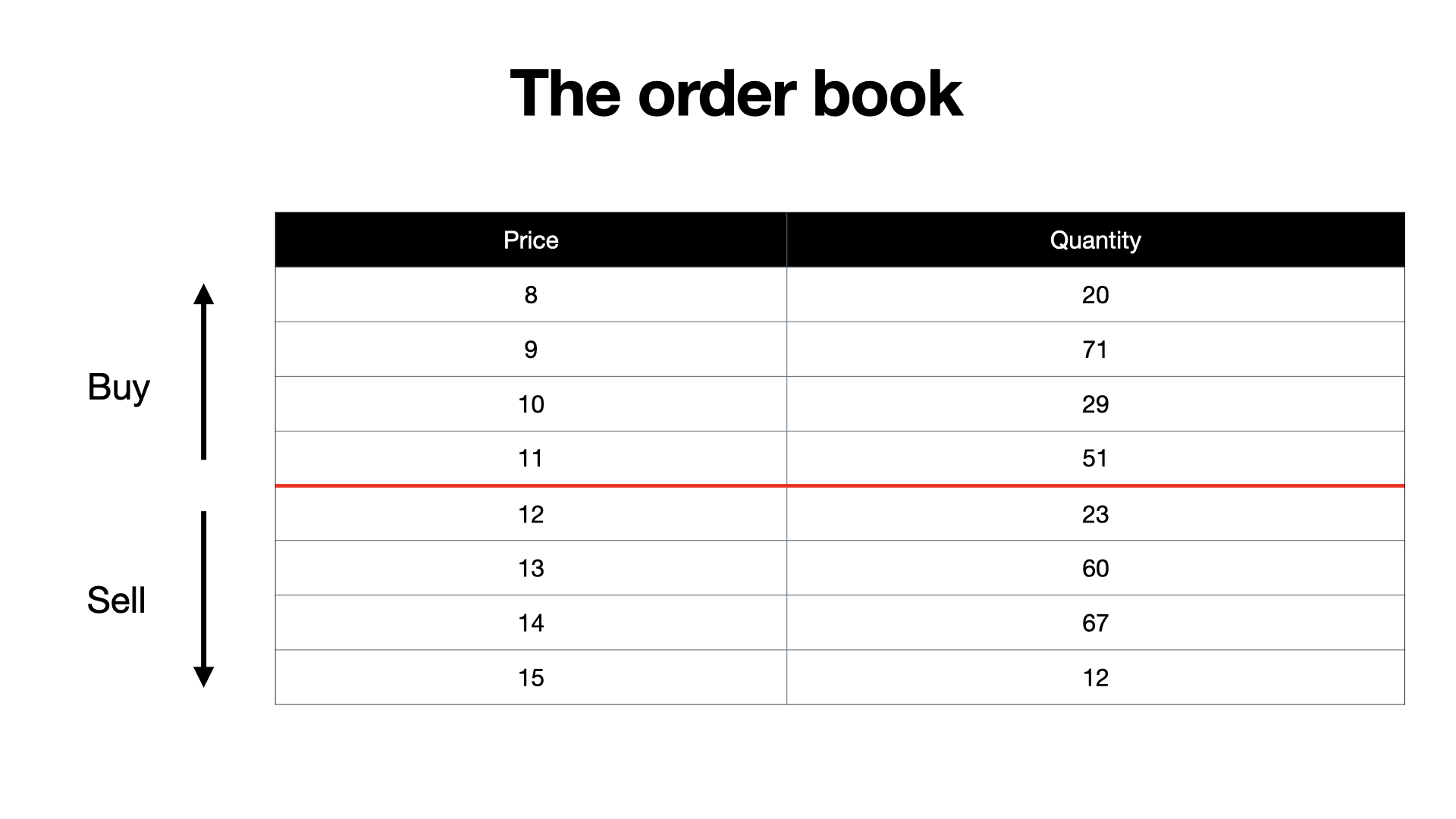
The heart of an exchange is really just this. A table, but we are going to call it an orderbook. The orderbook is sorted by price and is split into two sides, a buy side and a sell side.
The book keeps track of the quantities offered at a given price. It's important to note that each security you trade has its own dedicated order book.
In this order book on the buy side, what we're seeing is a demand to buy 20 shares at a price of 8 or better. Better meaning the buyer having to pay less.
On the other side, the sell side, you see that there is an offering to sell 12 shares at a price of 15 or better. Better meaning the buyer paying more.

Okay, but I think to really understand how an order book works, we have to look at an incoming order.
Our order is straightforward: I want to buy 20 shares for at most 12€, meaning if somebody is willing to sell their shares for 11€, I am also okay with it.
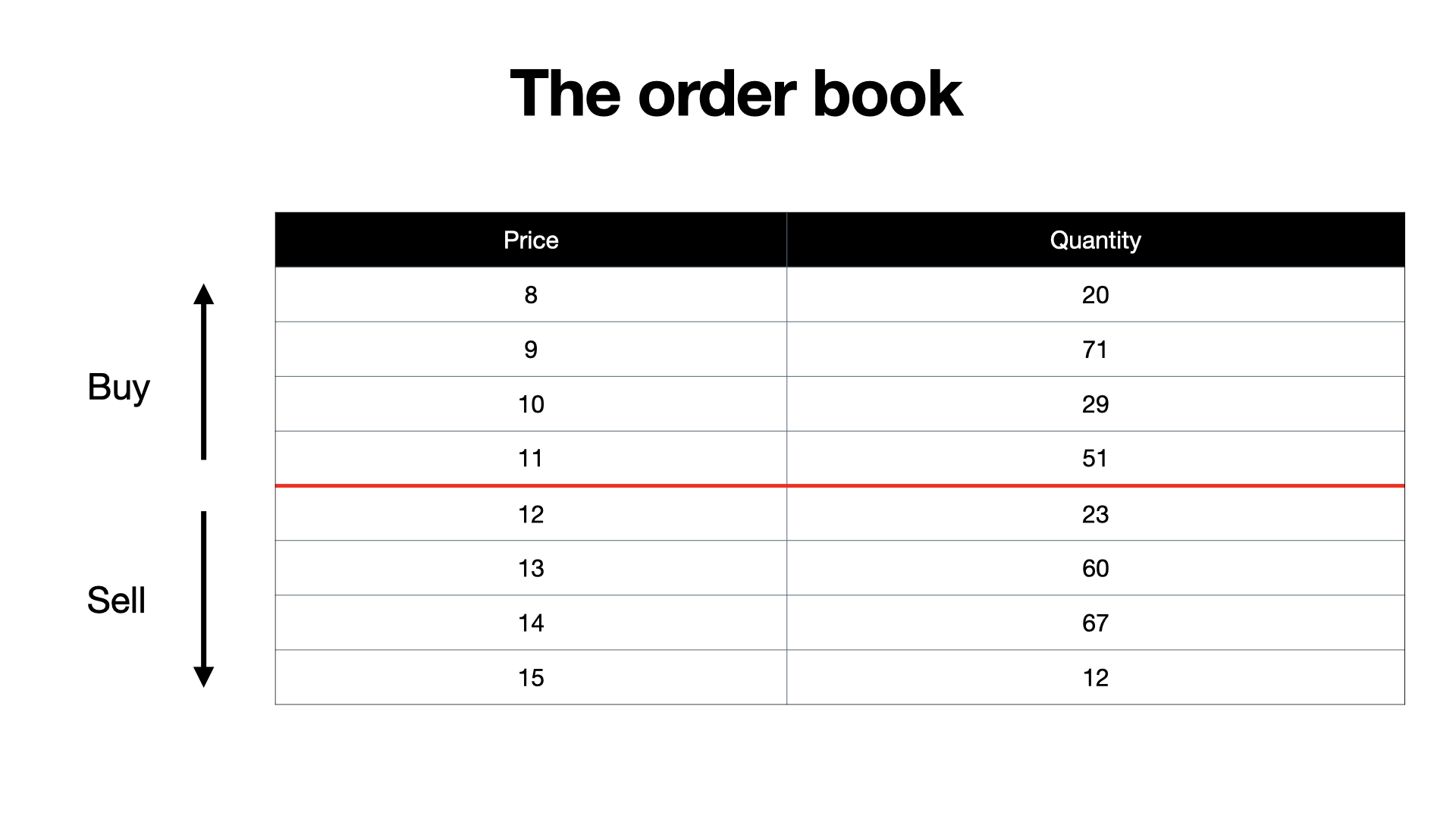
We start out with the same order book we just looked at.
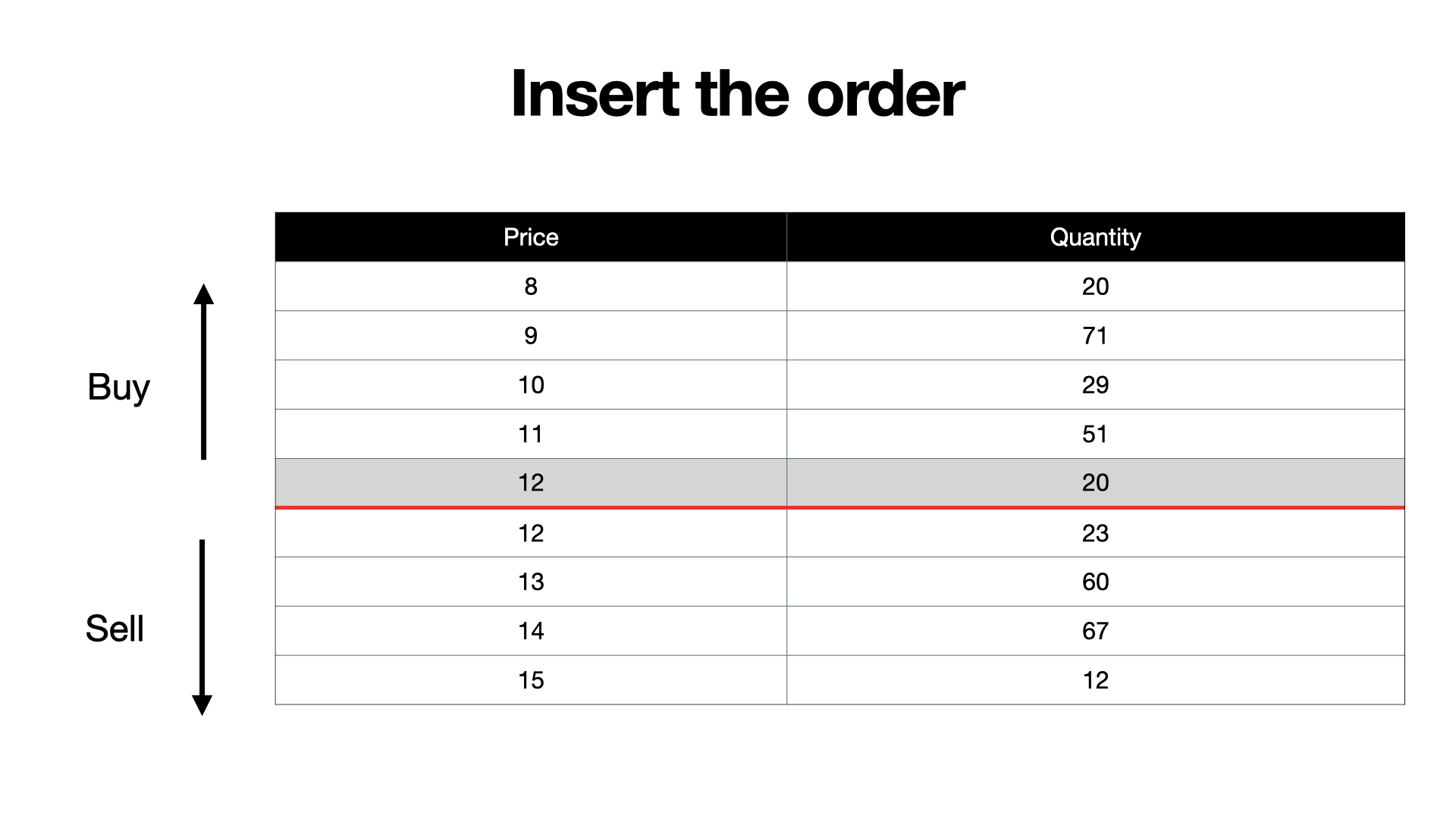
First, we are going to add the order to our order book. It's a buy order so naturally it goes on the buy side of the order book.
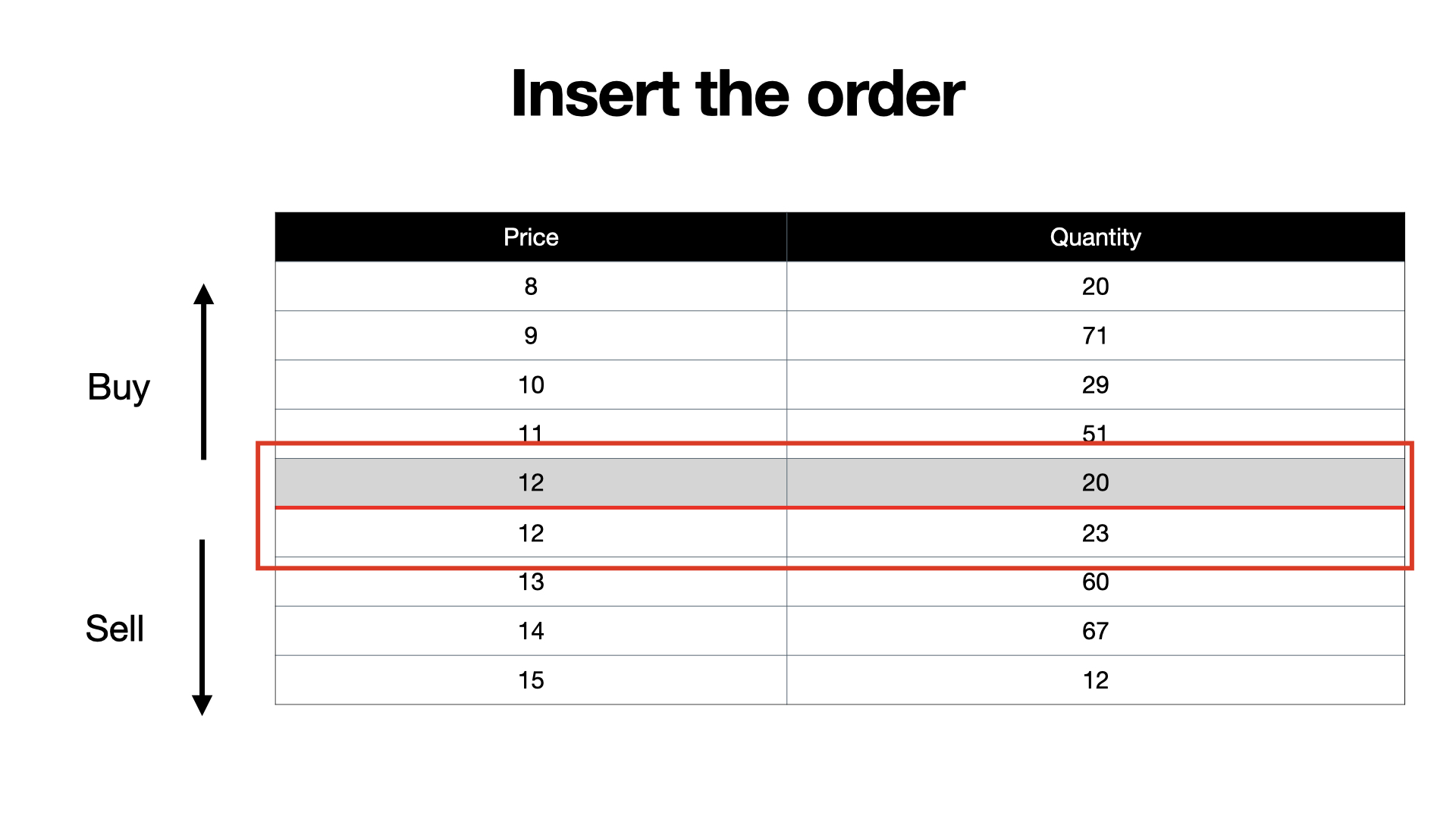
And oh look, there is an entry on the buy side and an entry on the sell side that share the same price. And you know what that means? We can match those two orders against each other and create a trade.
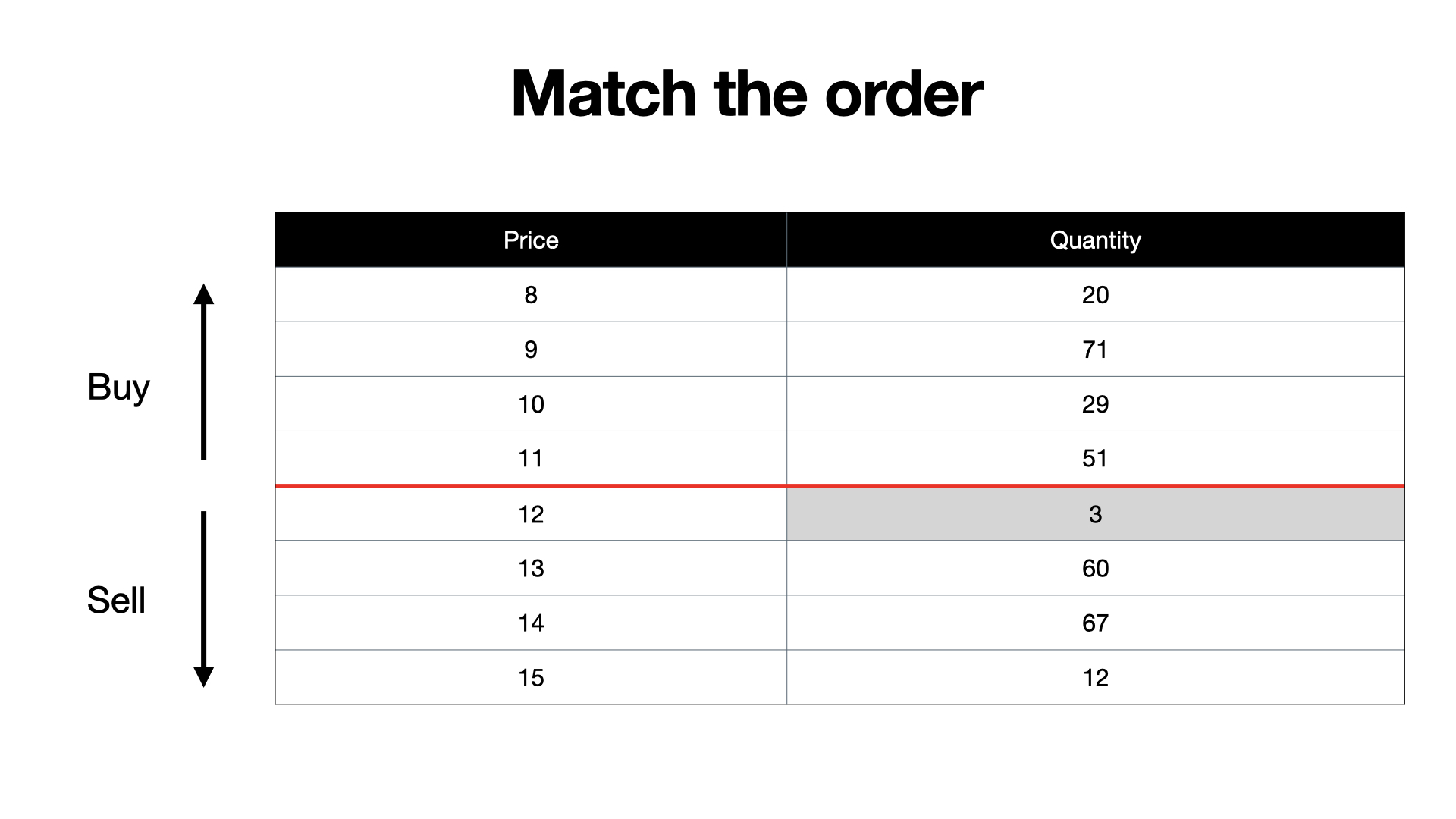
Finally, we need to update the order book because obviously after we matched those two orders against each other there are only 3 shares left offered to be sold at the 12€ price level.
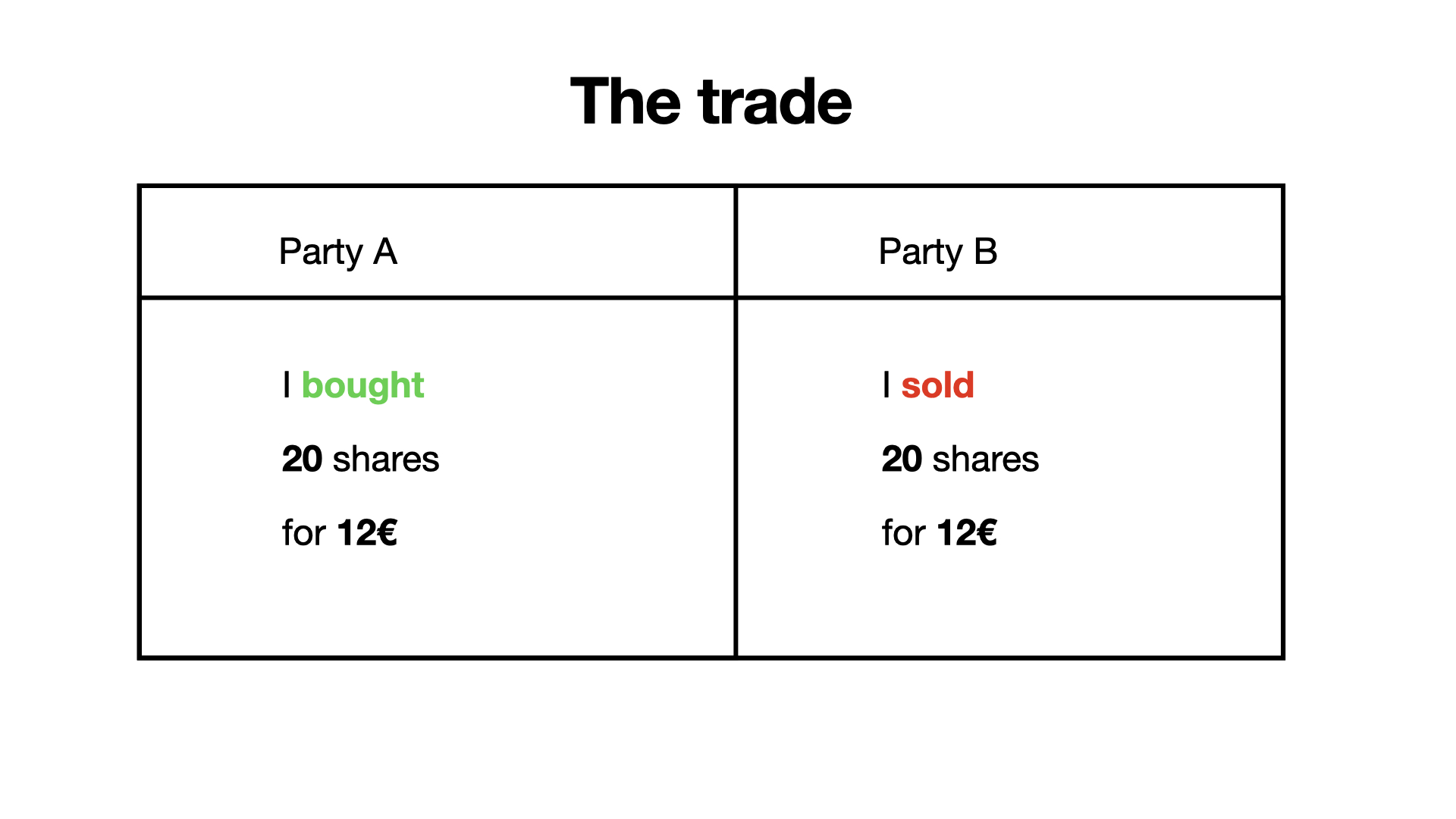
Let's look at the trade that we got out of all our matching action. You see, there are always two sides to a trade, one party who sold something and one party who bought something. If you can't find the other party for a trade, it may not be as real as you think. *Looking at you Bernie Madoff*

So now we know how we can match orders and what an order book is, but this is a computer program, isn't it? We need to talk about the data structures.

Remember the entries in the order book? We'll call each row in an order book a limit, because remember the listed prices are boundaries, we may be willing to pay 10€ for something, but if someone comes around offering it for 9€ we would also be okay with it.
Nothing really fancy, we have a price and a list of orders that make up the displayed quantity. Usually you use something like a linked list because this way you have fast inserts and can easily pop orders from each end of the list.
The order list acts as a queue. If for example you entered a buy order and afterwards someone else did so as well for the same price your order is going to be considered first to be matched, and only if your order is filled the order after yours is going to be matched.

Of course we have a limit order as well. This is just a plain old ruby object, nothing exciting here to see.

Then we have our trade. Remember, a trade is a matching of a buy and a sell order. Therefore, we need to reference a buy order and a sell order, along with the price and quantity that the two parties agreed to exchange.
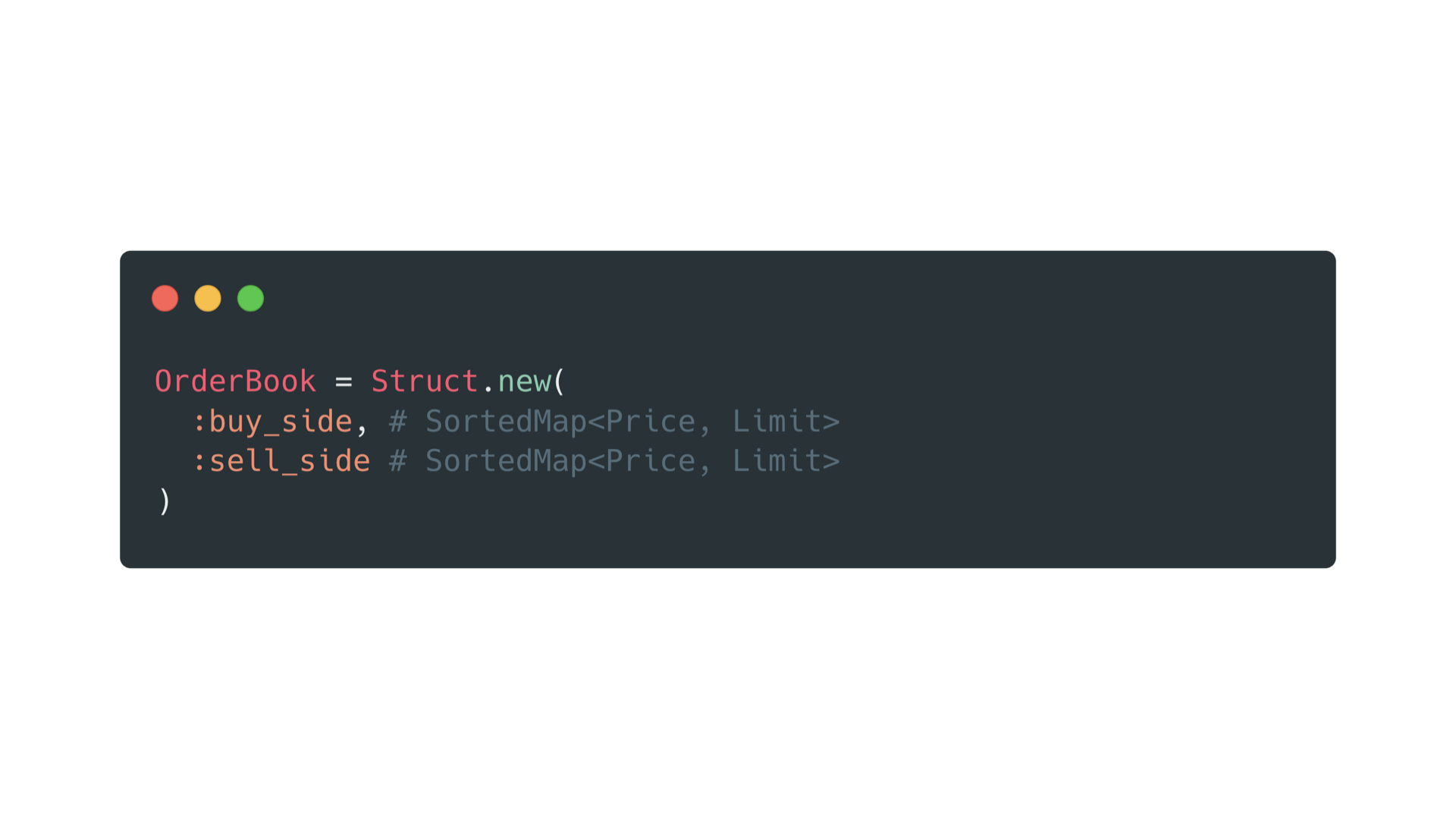
Obviously we also have an order book. Given that an order book always has two sides the buy and the sell side, we reflect that in the data.
Each side is some kind of associative sorted data structure, mapping a price to the limit entry. You can use a red-black tree to map your prices to limits. Which gives you a sweet O(log n) performance for all relevant use cases.

Okay, let's talk matching, more specifically the algorithm we are going to execute to match orders.
And I promise you, the word algorithm sounds as if it was complicated, but it's actually pretty simple.

First we get the buy order that is willing to pay the most and the sell order that offers to sell at the lowest price.
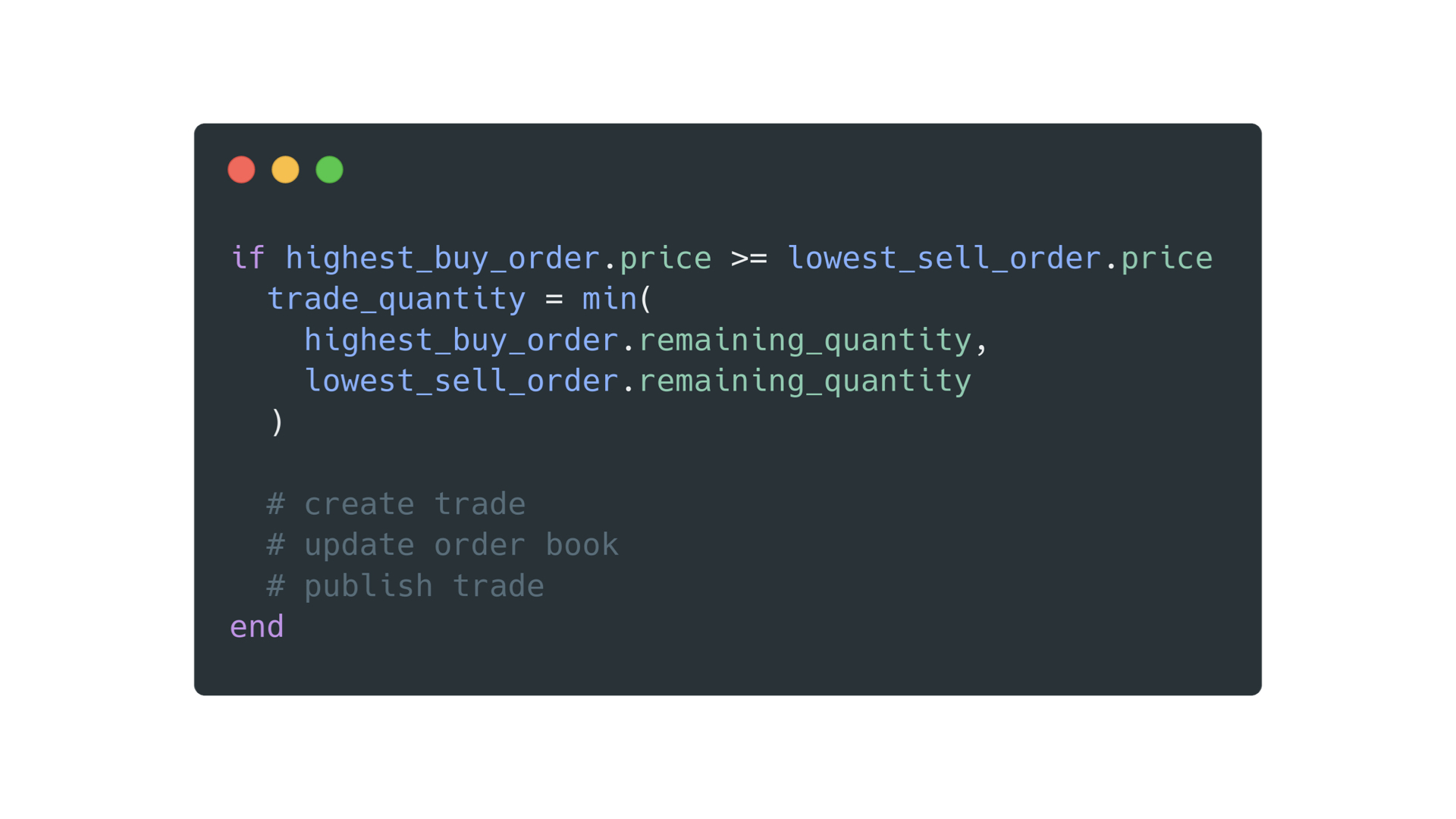
If those two orders overlap in price we can create a trade. First we are going to establish the quantity of the traded security we can exchange and then we are going to create a trade.
Afterwards we are going to update the order book sides and publish the trade.
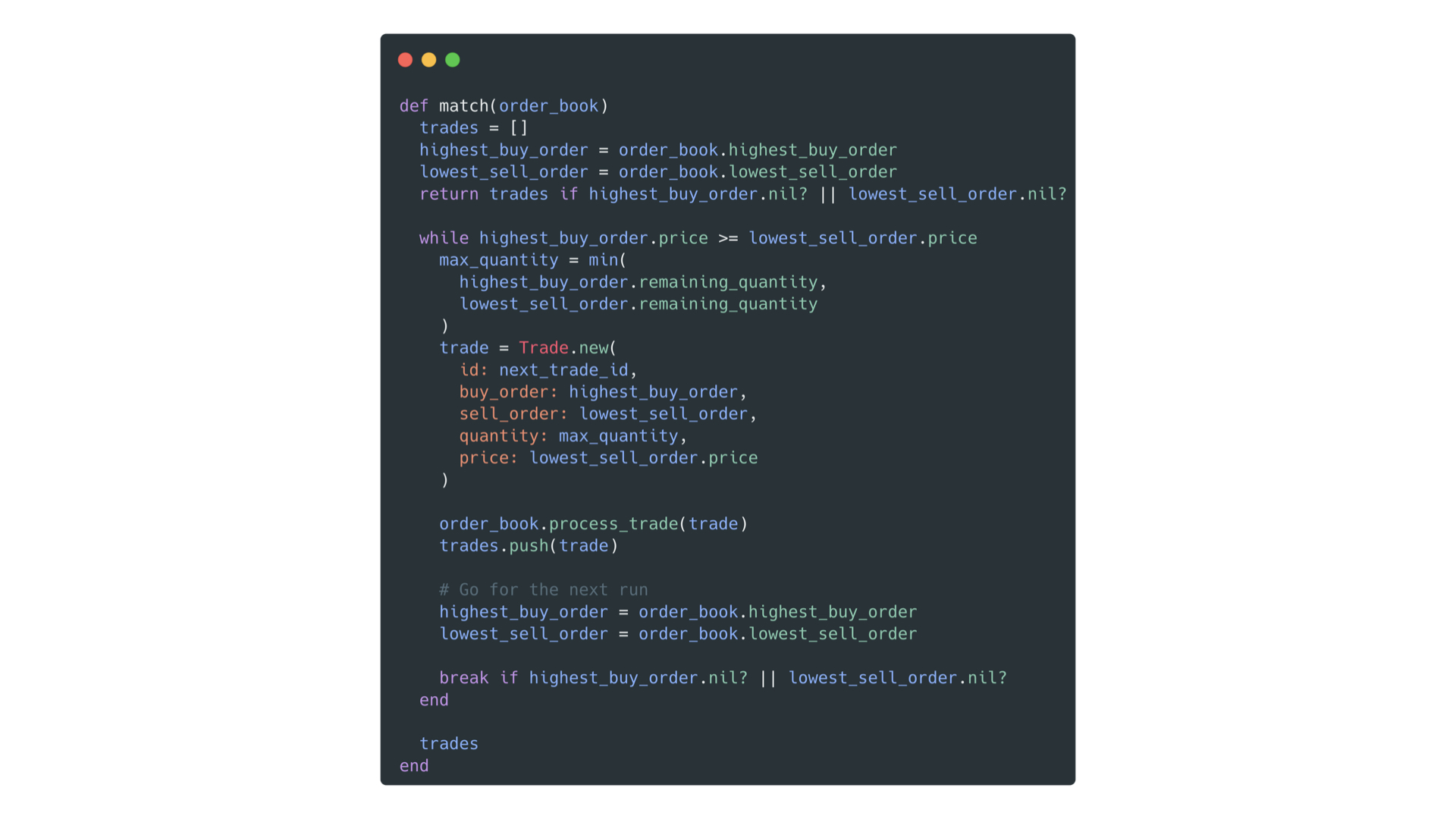
Admittedly this was a bit simplified, but the real version isn't much more complicated.
30 lines of ruby code, that's all.

We talked about the algorithms and the data structures by now, but the actually interesting computer science challenges are in the system you have to build to operate an exchange.

First, the requirements.
High availability is kind of a no-brainer. The system must maintain high availability. When trading begins in the morning and continues late into the night, with orders flooding in every second, the system cannot afford to go down.
Then there's auditability, think about it, if a trader fat fingered an order and is angry that it got matched, the trader may try to contest it. It's crucial to have a robust audit trail that can verify the occurrence of the order and demonstrate how it was matched.
Last we got determinism, that's a really tricky one. You want to be able to reproduce any state in an exchange. If something weird happens, you want to reproduce it. There are huge sums of money involved. You can't just shrug your shoulders and tell someone that you can't reproduce the bug using rspec, therefore everything should be fine.

Let's lay out some ground rules that will help us build a sturdy exchange.
Number one: we are not going to use multi threading in our exchange. There is going to be one while loop at the heart of our exchange that processes one order after another, no race conditions, no funny deadlock situations.

Then our second rule: we are going to build our matching engine in a way that it only works by reacting to incoming messages. All the necessary information will be part of those messages. We are not going to read the clock, we are not going to read files, no random() to spice things up. No IO dependency is going to mean that same input equals same output. Which will make our lives so much easier.
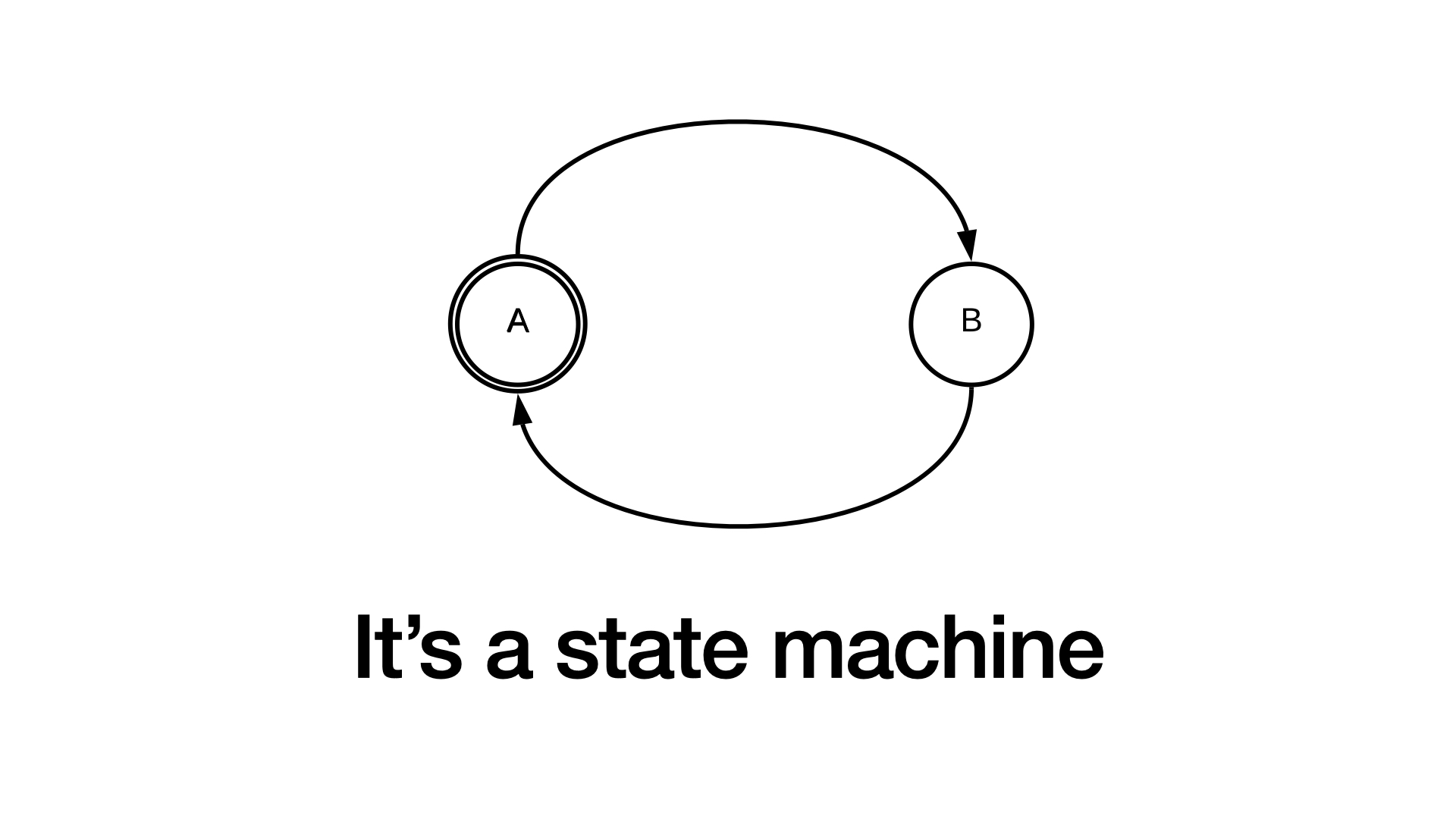
Maybe you remember state machines from your time at university, or that time a junior developer told you that this would have been way better when it was modeled as a state machine, side note: it would just be the same mess.
But let's not get carried away. State machines are pretty cool despite all of that because they allow us to model our system as a set of states and incoming messages manipulate that state, which is exactly what we want. We have a highly stateful system—our order book—and we want the orders to manipulate that state.
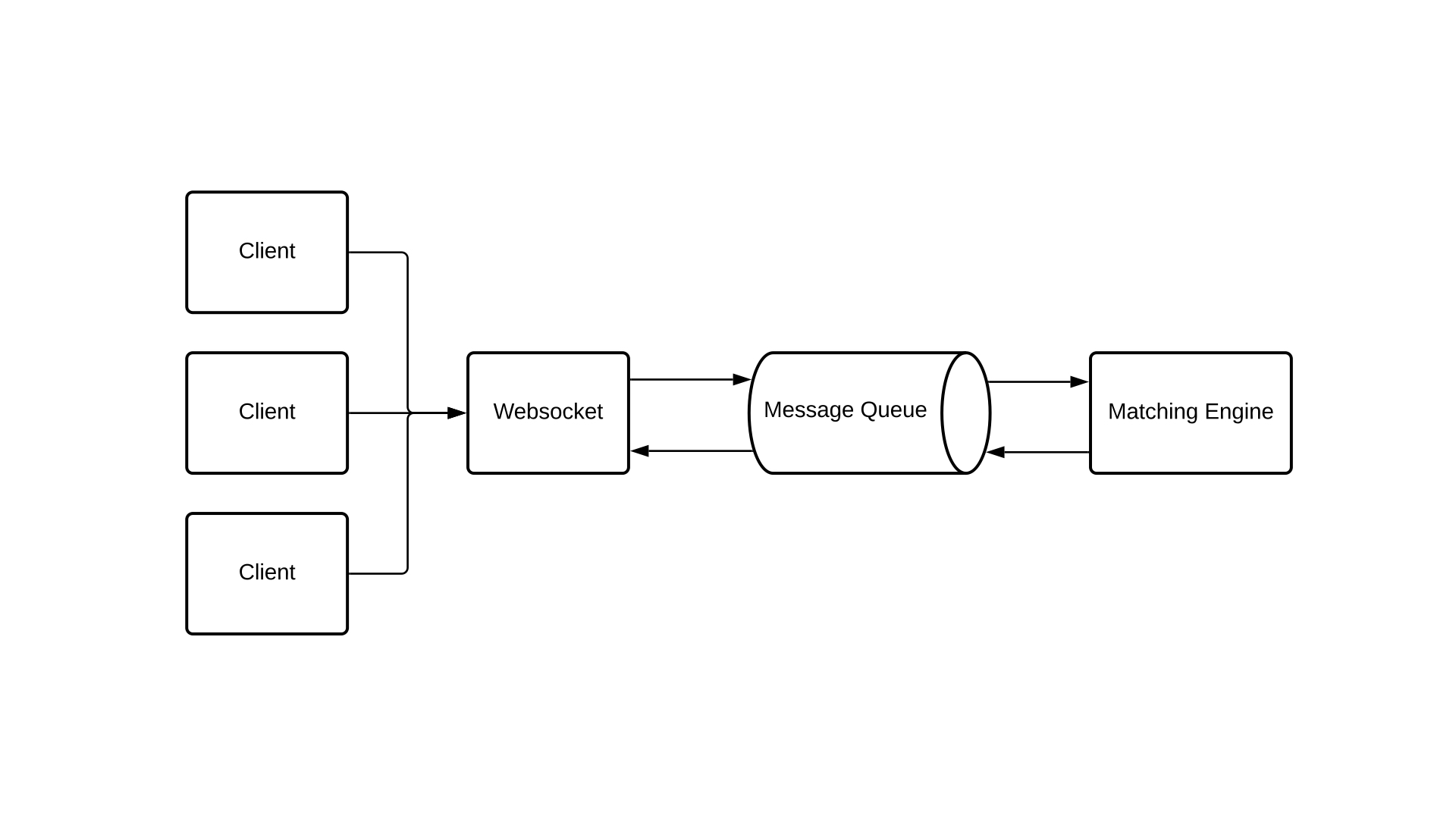
Really a very basic design for an exchange. We are going to use websockets to allow clients to connect to the exchange and every message we receive we put in a message queue and the matching engine then processes this message queue one by one and sends the resulting events out to the clients via the same message queue
By having the message queue as a choke point in the system we can establish total ordering. The message queue serves as the system's mechanism for serializing our chaotic request stream, enabling the matching engine to perform its primary function: keeping track of orders and matching them.

But wait, I hear you say. There's a big elephant in the room.

Where's our database? I don't see PostgreSQL. How are we going to persist anything?
Well, we are not going to use a relational database. Databases like PostgreSQL offer a plethora of guarantees and features, but for our system, we only require a very small set of features. Therefore, we are not going to use a relational database.

I know what you may think now, but trust me, it's going to work out fine.
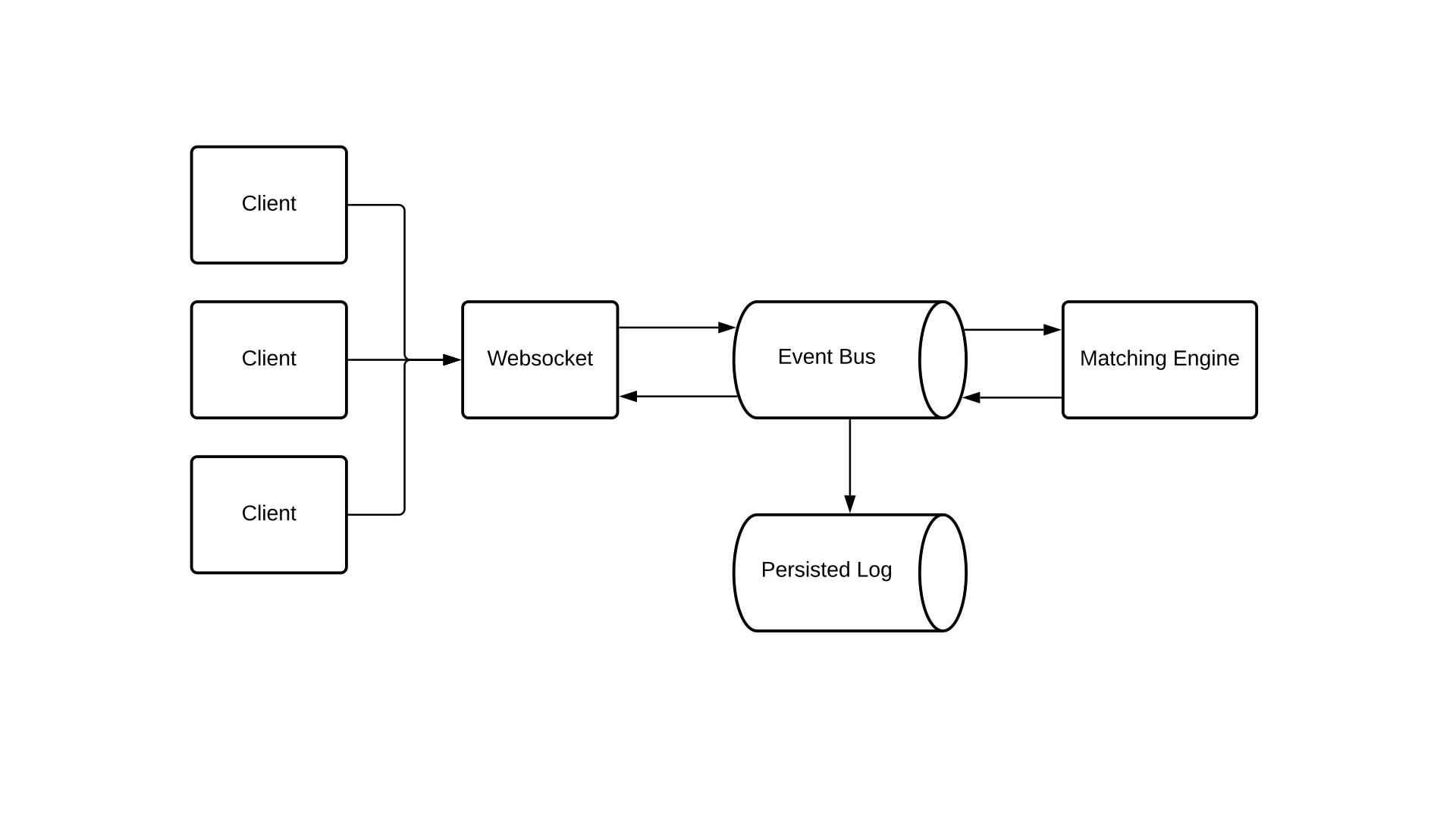
We still have to solve persistence. And we are going to do so by taking our message queue, renaming it to event bus and persisting the messages to disk. You can use all kinds of technologies here, you can implement your own write ahead log, or use a simple persisted key value store such as rocks db.

By now we solved the determinism by using a single threaded state machine to model our matching engine and we solved the auditability by storing all incoming and outgoing messages using a persisted log.
However, we have yet to solve the availability problems. Remember, it's generally considered bad practice to go down during a trading day.
Availability is a tricky one. We refused to use threads to have determinism and to only have one instance of the matching engine, but naturally if this one instance goes down we are done for.
We should definitely address this. While it is not great if the matching engine goes down, the bigger problem is our mean time to recovery. You would have to process the whole order stream from the start in order to recreate the matching engine state. That is clearly unfeasible.
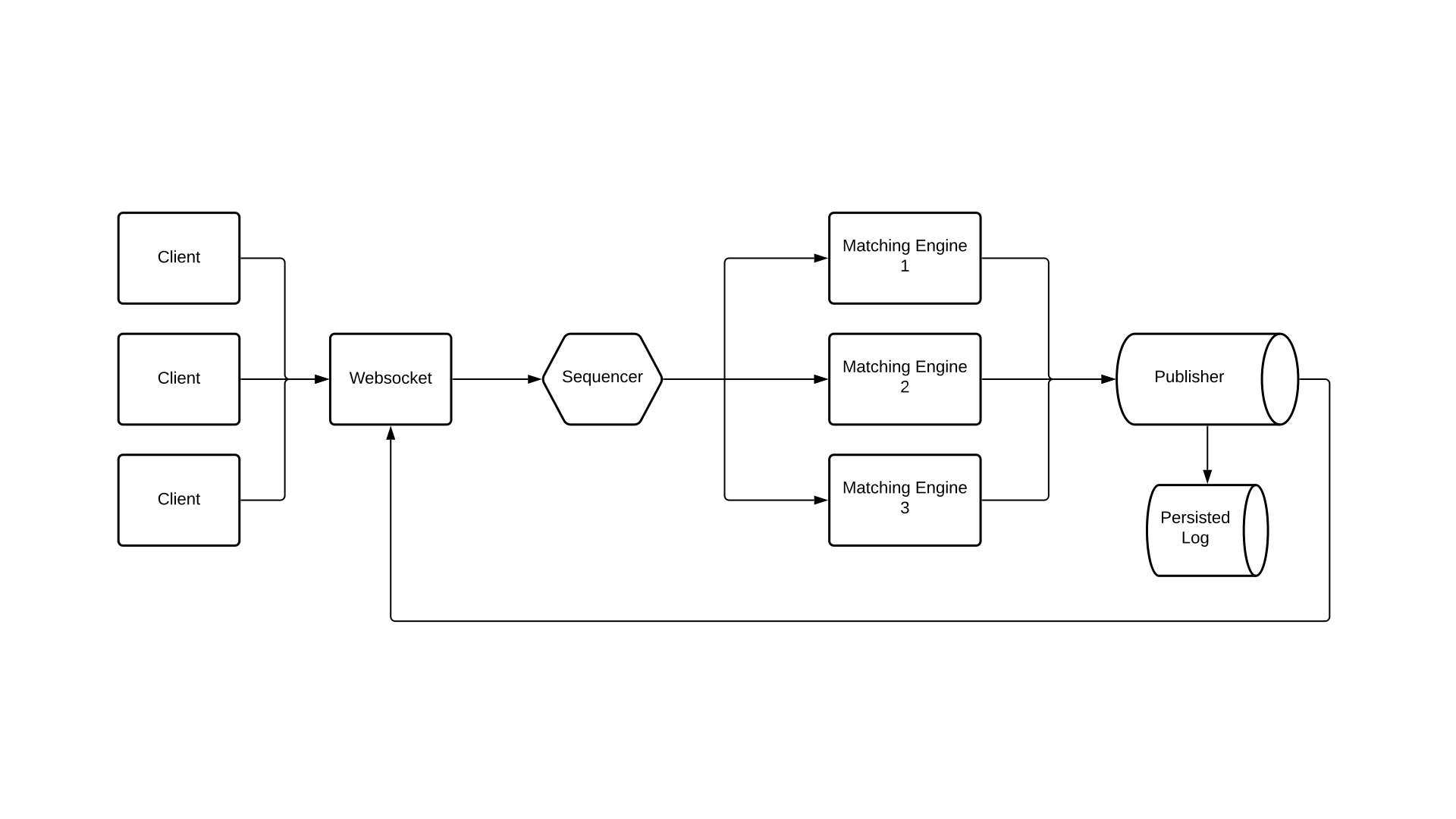
But what if we can change this? - First we are going to introduce a little choke point in the system. We'll call it a sequencer. The sequencer's responsibiity is it to take incoming messages establish an absolute ordering and forward the message to the matching engine.
But instead of just running one matching engine, we are going to run multiple instances, each of them receiving the same message stream. Remember, we built our matching engine as a state machine, which means same input messages result in the same output message.
Then at the end we are going to introduce a publisher. The publisher takes the messages from the individual matching engines and checks that the engines came to the same result.

Let's see how it works if one of the matching engine servers catches fire and we have to start a new matching engine.
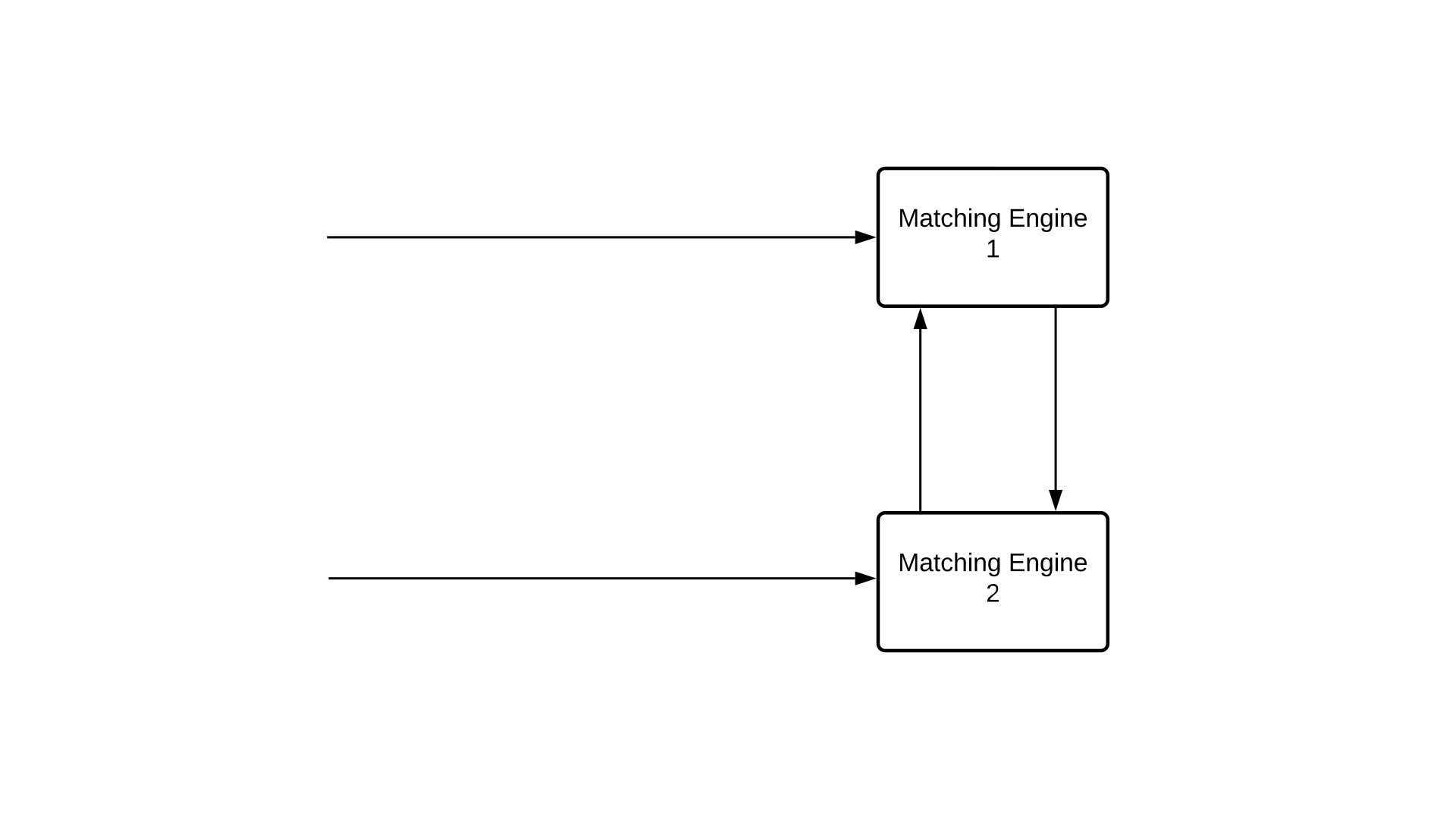
For this scenario we are going to assume matching engine 1 is the one that went down.
We are going to start a new one on a not so hot server and it starts receiving the incoming messages, but it won't produce any output messages yet. Before we can do so, matching engine one is going to ask one of the other matching engines, e.g. matching engine 2 to give us a snapshot of its state.
The state contains the current order book state, and everything else that is relevant, including the sequential id of the last processed message.
With this information, we can reconstruct the whole state. We are going to take the snapshot and apply all the messages we are already receiving. Remember we can easily do so because the state of our matching engine only depends on the incoming messages and nothing else.
Once we've caught up, we can resume producing output messages, and we're back online.

Let's wrap it up and do a little recap.

First: just because every project you worked on had a database doesn't mean that every project needs a database.
Think about what a database can offer and make an informed judgement whether you need those features.

Second: sometimes it's okay to just prevent the most catastrophic failure. In our case, we introduced redundancy only for the most critical part of our system, the matching engine and made sure that even in a complete loss of a matching engine we can continue operating.

Third: thinking about your state and modeling your system as a simple state machine without I/O can help you build reliable, easy to test systems.